You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Presort Software and Unicode
- Thread starter pabney
- Start date
Yes, but what about those special characters? In the attached Excel file all the names are correct. After import into Bulk Mailer they are not. Record 5 has a question mark in the name. Since the damage has already been done, no matter how I export the name is now wrong.
Attachments
namelessentity
Well-known member
What type of text files will it accept?
If you're on PC you might have luck exporting a .txt file as Unicode. Open it in Notepad, and under "save as" choose "ANSI".
We have a client that uses some really old database program that we have to do this for daily, maybe it will solve your problem.
EDIT: Just realized this converts the Č into a plain C, so it doesn't really solve the issue.
If you're on PC you might have luck exporting a .txt file as Unicode. Open it in Notepad, and under "save as" choose "ANSI".
We have a client that uses some really old database program that we have to do this for daily, maybe it will solve your problem.
EDIT: Just realized this converts the Č into a plain C, so it doesn't really solve the issue.
Last edited:
MailGuru
Well-known member
What type of text files will it accept?
If you're on PC you might have luck exporting a .txt file as Unicode. Open it in Notepad, and under "save as" choose "ANSI".
We have a client that uses some really old database program that we have to do this for daily, maybe it will solve your problem.
EDIT: Just realized this converts the Č into a plain C, so it doesn't really solve the issue.
I think that's what he's looking for. Internet research indicates that it must go through a UTF-8 (Unicode) to Ascii conversion. Did not realize that Notepad may do that automatically. Still, you'll need to manually eyeball the results to make sure it converted correctly (some Unicode UTF-8 characters have no ascii equivalent)
MaliGuru,
You are correct, that is what I am looking for. From all my research, unless the software supports UTF-8 then a conversion will have to take place, which means that some of the characters will be changed if there is no Ascii equivalent. This mostly affects extra data not address data, but it is still causing an issue. The only way I can combat it at present is to run the address only through Bulk Mailer, and re-linking the extra data to the new address information. Time consuming and error prone, in my opinion.
To me, the best solution is to find software that actually supports UTF-8, if it exists.
You are correct, that is what I am looking for. From all my research, unless the software supports UTF-8 then a conversion will have to take place, which means that some of the characters will be changed if there is no Ascii equivalent. This mostly affects extra data not address data, but it is still causing an issue. The only way I can combat it at present is to run the address only through Bulk Mailer, and re-linking the extra data to the new address information. Time consuming and error prone, in my opinion.
To me, the best solution is to find software that actually supports UTF-8, if it exists.
That is good it isn't in the address data as I don't think CASS/PAVE/etc.. and even NCOA would handle it. I know that GMC handles double byte files, which is like UTF-8, but I have yet to run across a presort software that handles it.
Maybe BCC's new API would be able to help? http://bccsoftware.com/integratec-api/
Maybe BCC's new API would be able to help? http://bccsoftware.com/integratec-api/
I never even thought of that. If CASS/PAVE/etc.. does not support Unicode, and from a quick search it does not (https://www.melissadata.com/tech/address-object-faq/general-information/index.asp?CATE=0#1), there is nothing I can do. That being said, the extra info that I am needing for merging into VDP should not get converted if it does not go through mail validation.
Thanks for the link to the API, I will take a look at it, but I suspect it will be over my head.
Thanks for the link to the API, I will take a look at it, but I suspect it will be over my head.
No Title
ASCII only defines the 128 code points that seven bit characters can produce. Text files are typically eight bits per character, since that's the smallest possible atomic data unit on almost any computer. The extra eighth bit doubles the possible code points to 256. Most text files, CSV files, etc. seen in the United States don't have any bytes that use the extra 128 values that eight bits give you over 7-bit ASCII, and therefore are unambiguous since there aren't any commonly used encoding schemes that don't match ASCII for those lowest 128 values.
When you have a CSV file that does contain higher, non-ASCII bytes, there isn't really a single, unambiguous interpretation. We can't fit all the characters everyone in the world wants to use into 256 slots, so there are lots of encodings out there. Without some sort of out-of-band information (e.g., Mac OS X has a text encoding attribute it tags text files with) or some magic code at the beginning of the file, you just have to guess and see what looks right. Solving this problem is the purpose of Unicode and its related encodings.
Unicode is a character set, not an encoding. It provides an extremely large mapping of characters to numbers. You can't really have a "Unicode" encoded file. You can have a "UTF-8," "UTF-16LE," or various other encodings that are strongly connected to Unicode. The UTF-16 encodings will map every two bytes to a single character, except for a largely undefined range of characters that map to four bytes. This isn't too handy in the United States, because most of our files will double in size when converted to one of these, and software definitely has to be prepared to interpret it.
UTF-8 tends to be the most useful. Every standard ASCII character gets encoded with one byte, exactly the same as it would in any other common encoding. Anything non-ASCII gets encoded with a variable-length sequence. This keeps our files small while allowing non-ASCII characters, and without limiting us to only 128 extra non-ASCII characters, like most of the other encodings do.
Most software that runs on Windows and does not provide encoding options appears to use Windows 1252 encoding. That gives us a fair amount of accented roman characters to add on top of ASCII.
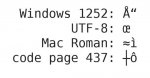
Attached is a test file. There is a single column, with one header row and one data row. It contains valid data for each of four different common encodings, but will look different with each one depending on how the software interprets it. I've also attached a legend of how the single data "cell" will look depending upon the encoding. Once you know what encoding your software is assuming, you can save your data correctly (as long as it is using an encoding that provides the characters that you need).
ASCII only defines the 128 code points that seven bit characters can produce. Text files are typically eight bits per character, since that's the smallest possible atomic data unit on almost any computer. The extra eighth bit doubles the possible code points to 256. Most text files, CSV files, etc. seen in the United States don't have any bytes that use the extra 128 values that eight bits give you over 7-bit ASCII, and therefore are unambiguous since there aren't any commonly used encoding schemes that don't match ASCII for those lowest 128 values.
When you have a CSV file that does contain higher, non-ASCII bytes, there isn't really a single, unambiguous interpretation. We can't fit all the characters everyone in the world wants to use into 256 slots, so there are lots of encodings out there. Without some sort of out-of-band information (e.g., Mac OS X has a text encoding attribute it tags text files with) or some magic code at the beginning of the file, you just have to guess and see what looks right. Solving this problem is the purpose of Unicode and its related encodings.
Unicode is a character set, not an encoding. It provides an extremely large mapping of characters to numbers. You can't really have a "Unicode" encoded file. You can have a "UTF-8," "UTF-16LE," or various other encodings that are strongly connected to Unicode. The UTF-16 encodings will map every two bytes to a single character, except for a largely undefined range of characters that map to four bytes. This isn't too handy in the United States, because most of our files will double in size when converted to one of these, and software definitely has to be prepared to interpret it.
UTF-8 tends to be the most useful. Every standard ASCII character gets encoded with one byte, exactly the same as it would in any other common encoding. Anything non-ASCII gets encoded with a variable-length sequence. This keeps our files small while allowing non-ASCII characters, and without limiting us to only 128 extra non-ASCII characters, like most of the other encodings do.
Most software that runs on Windows and does not provide encoding options appears to use Windows 1252 encoding. That gives us a fair amount of accented roman characters to add on top of ASCII.
Attached is a test file. There is a single column, with one header row and one data row. It contains valid data for each of four different common encodings, but will look different with each one depending on how the software interprets it. I've also attached a legend of how the single data "cell" will look depending upon the encoding. Once you know what encoding your software is assuming, you can save your data correctly (as long as it is using an encoding that provides the characters that you need).
Attachments
I never even thought of that. If CASS/PAVE/etc.. does not support Unicode, and from a quick search it does not (https://www.melissadata.com/tech/address-object-faq/general-information/index.asp?CATE=0#1), there is nothing I can do. That being said, the extra info that I am needing for merging into VDP should not get converted if it does not go through mail validation.
Thanks for the link to the API, I will take a look at it, but I suspect it will be over my head.
I didn't try it, but I guess you can do this, you just skip printing First name Last Name from the presorted records, but print those two fileds from original database, that should solve the problem
for example
IMB bar code here (from mailing software)
First Name, Last Name (from origianl file)
address 1(mailing)
address 2(mailing)
....
MailGuru
Well-known member
Hey pabney, looks like you've got a real mess on your hands. I've tried several different approaches, but, can't get it to convert properly. Any chance that the client originator has other export options besides unicode? If not, only solution I see is to parse out the mailing info, put that through your cass & presort process, then attach back together after output. Only problem I see with that approach is, if your need to run NCOA on the file to get the presort discount, NCOA will need at least the last name field along with the address to match properly.
Kyle,
Thank you very much for the explanation. I now have a much better understanding of what is going on, and the proper terminology of what I need. So I guess what I am actually looking for is mail software that can use UTF-8. I can tell from your excellent legend that my current software is using Windows 1252. This seems to work very well MOST of the time, but not all of the time.
MailGuru,
There seems to be a bit of confusion here. The client is giving me an Excel file, that I directly import into Bulk Mailer. The text is correct in Excel, not in Bulk Mailer. I can export out of Excel into a "Unicode Text" file (which is where I got the wrong terminology for my original post), which is a tab delimited file using UTF-8 encoding. (Thanks to Kyle posting above, I now know this.) In this text file, my variable data software, XMPie, gets the correct character. It is only when I send it through Bulk Mailer that I have an issue. It is also not so much an issue with the address data as much as the extra data that is needed for various VDP tasks.
For now I can see 4 ways to approach this issue.
1. Ignore it. What we are currently doing works MOST of the time. (Not really me. I'm a bit obsessive with things like this.)
2. Find Mail Presort software that can utilize UTF-8 encoding. This would fix the issue with the extra data. The address data I can blame on the USPS. (This does not seem likely either.)
3. Upgrade XMPie to the PersonalEffect Print level. This would allow me to connect to multiple tables, the presorted one and the original one.
4. Do what I have been doing and what you are suggesting. Parse out the mail info, process, and reattach to the original data.
Thanks everyone for the help, and if you see an option that I have missed, or know of mail software that can use the UTF-8 encoding for the extra data.
Thank you very much for the explanation. I now have a much better understanding of what is going on, and the proper terminology of what I need. So I guess what I am actually looking for is mail software that can use UTF-8. I can tell from your excellent legend that my current software is using Windows 1252. This seems to work very well MOST of the time, but not all of the time.
MailGuru,
There seems to be a bit of confusion here. The client is giving me an Excel file, that I directly import into Bulk Mailer. The text is correct in Excel, not in Bulk Mailer. I can export out of Excel into a "Unicode Text" file (which is where I got the wrong terminology for my original post), which is a tab delimited file using UTF-8 encoding. (Thanks to Kyle posting above, I now know this.) In this text file, my variable data software, XMPie, gets the correct character. It is only when I send it through Bulk Mailer that I have an issue. It is also not so much an issue with the address data as much as the extra data that is needed for various VDP tasks.
For now I can see 4 ways to approach this issue.
1. Ignore it. What we are currently doing works MOST of the time. (Not really me. I'm a bit obsessive with things like this.)
2. Find Mail Presort software that can utilize UTF-8 encoding. This would fix the issue with the extra data. The address data I can blame on the USPS. (This does not seem likely either.)
3. Upgrade XMPie to the PersonalEffect Print level. This would allow me to connect to multiple tables, the presorted one and the original one.
4. Do what I have been doing and what you are suggesting. Parse out the mail info, process, and reattach to the original data.
Thanks everyone for the help, and if you see an option that I have missed, or know of mail software that can use the UTF-8 encoding for the extra data.
The Bulk Mailer software is taking in a CSV/text file you've saved from Excel (not an Excel file) right?
For your example data, if you were to save it as a UTF-8 (or whatever Excel might wrongly call it) CSV file, then import it into Bulk Mailer, I would expect names like "AARÓN" and "Soupçon" to not be correct if Windows 1252 is the assumption made by the Bulk Mailer software. Even though those characters are representable in Windows 1252, they would not be encoded correctly for software expecting Windows 1252 if the file were saved with UTF-8 encoding. The name "Karel Čapek" does contain a character that is not representable with Windows 1252, and I believe that is the record you mentioned having a question mark substitution occur in.
Can you verify that if you save a UTF-8 CSV from Excel using your sample data, then import into Bulk Mailer, that the other four names are not represented correctly, in addition to "Karel ÄŒapek?"
For your example data, if you were to save it as a UTF-8 (or whatever Excel might wrongly call it) CSV file, then import it into Bulk Mailer, I would expect names like "AARÓN" and "Soupçon" to not be correct if Windows 1252 is the assumption made by the Bulk Mailer software. Even though those characters are representable in Windows 1252, they would not be encoded correctly for software expecting Windows 1252 if the file were saved with UTF-8 encoding. The name "Karel Čapek" does contain a character that is not representable with Windows 1252, and I believe that is the record you mentioned having a question mark substitution occur in.
Can you verify that if you save a UTF-8 CSV from Excel using your sample data, then import into Bulk Mailer, that the other four names are not represented correctly, in addition to "Karel ÄŒapek?"
Kyle,
No csv is used. Bulk Mailer opens the Excel file directly. The AARÓN and Soupçon do come in correctly. The Karel Čapek name is Karel ?apek. If I import your csv file from above I get the Windows 1252 symbol. If I do export from excel as a UTF-8 and import the tab delimited text file AARÓN and Soupçon still come in correctly and the Karel Čapek name comes in as Karel Capek. If I save out of Excel as a csv (no options for encoding) and import I get the same as importing the Excel file directly.
No csv is used. Bulk Mailer opens the Excel file directly. The AARÓN and Soupçon do come in correctly. The Karel Čapek name is Karel ?apek. If I import your csv file from above I get the Windows 1252 symbol. If I do export from excel as a UTF-8 and import the tab delimited text file AARÓN and Soupçon still come in correctly and the Karel Čapek name comes in as Karel Capek. If I save out of Excel as a csv (no options for encoding) and import I get the same as importing the Excel file directly.
I'm going to shorten my reference to the person's name to just their last name, so this page hopefully won't be the first hit on a Google search for them. ")
Is "Capek" an acceptable substitution for "Čapek?" I was eventually planning to arrive at a solution that would give you "Capek," since that's the best we can do if we're truly trapped within the confines of Windows 1252, and a person with such a name is probably used to getting mail with plain instead of accented roman letters in their name (could you imagine the person behind the counter at the DMV in trying to figure out how to type "Č" on their keyboard?). It sounds like exporting UTF-8 from Excel is getting you there, which is one less step than the solution I had in mind.
I'm still a bit confused about my test file being interpreted as Windows 1252 while your UTF-8 encoded file is interpreted correctly (if "AARÓN" is truly encoded as UTF-8 and is interpreted correctly, then the same process should interpret the data in the test file as "Å“" instead of "Ã…“"). My file had an extension of "csv." Perhaps yours has "txt" and that causes a different interpretation. Try renaming your file (the file that renders "AARÓN" and "Soupçon" correctly but "ÄŒapek" as "Capek") to the same filename as my test file ("encoding test.csv"), then import it with the same import settings, context, etc., and verify the interpretation stays the same: my file as "Ã…“" and yours as "AARÓN" and "Capek." Then put your mostly-correct UTF-8 file in a ZIP file and attach it here. I'd like to verify with certainty that it is UTF-8 encoded. If it is, then your software can already interpret UTF-8 correctly when you give it the UTF-8 encoded file exported from Excel, and the problem with "Capek" instead of "ÄŒapek" could actually be something like a limitation in the font used to render the text.
Is "Capek" an acceptable substitution for "Čapek?" I was eventually planning to arrive at a solution that would give you "Capek," since that's the best we can do if we're truly trapped within the confines of Windows 1252, and a person with such a name is probably used to getting mail with plain instead of accented roman letters in their name (could you imagine the person behind the counter at the DMV in trying to figure out how to type "Č" on their keyboard?). It sounds like exporting UTF-8 from Excel is getting you there, which is one less step than the solution I had in mind.
I'm still a bit confused about my test file being interpreted as Windows 1252 while your UTF-8 encoded file is interpreted correctly (if "AARÓN" is truly encoded as UTF-8 and is interpreted correctly, then the same process should interpret the data in the test file as "Å“" instead of "Ã…“"). My file had an extension of "csv." Perhaps yours has "txt" and that causes a different interpretation. Try renaming your file (the file that renders "AARÓN" and "Soupçon" correctly but "ÄŒapek" as "Capek") to the same filename as my test file ("encoding test.csv"), then import it with the same import settings, context, etc., and verify the interpretation stays the same: my file as "Ã…“" and yours as "AARÓN" and "Capek." Then put your mostly-correct UTF-8 file in a ZIP file and attach it here. I'd like to verify with certainty that it is UTF-8 encoded. If it is, then your software can already interpret UTF-8 correctly when you give it the UTF-8 encoded file exported from Excel, and the problem with "Capek" instead of "ÄŒapek" could actually be something like a limitation in the font used to render the text.
joshlindsay
Well-known member
Not an ideal solution but once you get used to it shouldn't add too much time and no expensive Personal Effect licence needed.
Append a unique ID to each record (if not already there).
Run your data through Presort
Upload original and presorted data to MS Access or MySQL as 2 tables.
Query tables matching ID number and get names from original and address from presorted.
We do this regularly as clients we handle mailings to the same list frequently. Client would send us original list again but with records taken out. We would run a query to get the new complete data to use with a saved SQL statement.
Append a unique ID to each record (if not already there).
Run your data through Presort
Upload original and presorted data to MS Access or MySQL as 2 tables.
Query tables matching ID number and get names from original and address from presorted.
We do this regularly as clients we handle mailings to the same list frequently. Client would send us original list again but with records taken out. We would run a query to get the new complete data to use with a saved SQL statement.
No Title
kyle,
Sorry it took so long to get back to you, but the end of last week just turned into a bear.
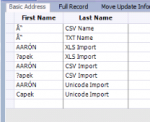
I am attaching a zip file of the different files I imported as well as a screen shot of how they imported.
I sincerely do appreciate the work you are putting into helping me with this.
kyle,
Sorry it took so long to get back to you, but the end of last week just turned into a bear.
I am attaching a zip file of the different files I imported as well as a screen shot of how they imported.
I sincerely do appreciate the work you are putting into helping me with this.
Attachments
Don't worry about not getting back to me quickly. I'm certainly in no hurry!
The file "names.csv" is Windows 1252. I can only tell that because that is the interpretation that yields the most correct file - there isn't anything in the file data that explicitly marks it as a Windows 1252 file. The "Ó" character is available in Windows 1252, so it is encoded correctly. The "Č" is not available in Windows 1252, and it is encoded as a question mark. The question mark in "?apek" is appearing because it's a question mark in the file, not because your software is reading a character it cannot understand or represent. Rather, it is actually encoded in the file as a literal question mark - what you would expect to be in the file if the person's name were actually "?apek." The software (I'm assuming Excel) that is saving the file is using Windows 1252, and its method for recording an unencodable character is to change it to a question mark. A more useful solution would be for it to replace the character with the best available substitute in Windows 1252, since "C" is a better representation of "Č" than "?" is. Most software does not do this, however, and you get the question marks - typically with a warning that the file could not be correctly encoded, but I wouldn't be surprised if Excel cannot warn you.
The files "encoding test.txt" and "encoding test.csv" are identical files, encoded as UTF-8 (without anything in the file data to mark them as such), and your software is interpreting them as Windows 1252.
The file "names.xlsx" is of course an Excel file. The names are encoded within that file as UTF-8, and your software appears to be interpreting it correctly, with the exception of characters that would not be encodable if the data were converted to Windows 1252 encoding.
The file "names.xlsx.txt" is UTF-16LE encoded, and does contain a "byte order mark" at the beginning which marks it as UTF-16LE. UTF-16 uses two bytes for every character, and UTF-16LE means "little endian" - the bytes are stored with the least-significant byte last.
It looks like your software expects most files to be Windows 1252, but recognizes the UTF-16LE byte order mark and changes its interpretation to correctly import such files. Since you're seeing "Capek" instead of "Čapek" when importing the UTF-16LE file, one of two things is probably happening. The software's internal data encoding may be Windows 1252, and it is changing "Č" to "C" on import since there is no way of representing "Č" in Windows 1252. If that is the case, it means your software is doing a more graceful degradation to "C" instead of "?" like what Excel did when saving your Windows 1252 CSV file. --OR-- it is actually the character "Č" but is rendered in a font that uses a glyph identical to "C" for that character. If a font designer didn't feel like making a bunch of seldom-used glyphs, they may have just duplicated the simple roman glyphs for those characters rather than leaving them undefined. That is probably less likely than the first scenario, since your Excel file import yields a question mark.
In either case, it means your software is behaving a little differently when importing an Excel file versus a UTF-16LE text file. The Excel file is UTF-8, and it is reading that correctly. The text file is UTF-16LE, and it is reading that correctly also. However, for the Excel file, it is changing the "Č" to a "?," and for the UTF-16LE file, it is changing it to "C." Perhaps they used some software library that's available out there for the part of their software that interprets Excel data, that library is converting to Windows 1252, and it does the more common question mark substitution. The import process for UTF-16LE is being a bit smarter about it.
There probably isn't a solution to make your software show "Č" unless it's a font problem and you can change the font, or it's converting to Windows 1252 and there is a preference somewhere that can change that. If "C" is acceptable, you can go the UTF-16LE route. The downside with UTF-16 encodings is that your file size is going to be about double what it would be with UTF-8, and if you need to look at those files with other software, they may not handle it well (UTF-8 would look fine in unaware applications except for the non-ASCII characters, which would probably still be saved correctly).
I've attached a new version of the test file. It is UTF-8 as before, but includes a UTF-8 byte order mark which may cause your software to recognize it correctly. Byte order marks are not generally recommended for UTF-8 files, but that could be a way to get your software to recognize it correctly if you don't have import options that would force it to.
The file "names.csv" is Windows 1252. I can only tell that because that is the interpretation that yields the most correct file - there isn't anything in the file data that explicitly marks it as a Windows 1252 file. The "Ó" character is available in Windows 1252, so it is encoded correctly. The "Č" is not available in Windows 1252, and it is encoded as a question mark. The question mark in "?apek" is appearing because it's a question mark in the file, not because your software is reading a character it cannot understand or represent. Rather, it is actually encoded in the file as a literal question mark - what you would expect to be in the file if the person's name were actually "?apek." The software (I'm assuming Excel) that is saving the file is using Windows 1252, and its method for recording an unencodable character is to change it to a question mark. A more useful solution would be for it to replace the character with the best available substitute in Windows 1252, since "C" is a better representation of "Č" than "?" is. Most software does not do this, however, and you get the question marks - typically with a warning that the file could not be correctly encoded, but I wouldn't be surprised if Excel cannot warn you.
The files "encoding test.txt" and "encoding test.csv" are identical files, encoded as UTF-8 (without anything in the file data to mark them as such), and your software is interpreting them as Windows 1252.
The file "names.xlsx" is of course an Excel file. The names are encoded within that file as UTF-8, and your software appears to be interpreting it correctly, with the exception of characters that would not be encodable if the data were converted to Windows 1252 encoding.
The file "names.xlsx.txt" is UTF-16LE encoded, and does contain a "byte order mark" at the beginning which marks it as UTF-16LE. UTF-16 uses two bytes for every character, and UTF-16LE means "little endian" - the bytes are stored with the least-significant byte last.
It looks like your software expects most files to be Windows 1252, but recognizes the UTF-16LE byte order mark and changes its interpretation to correctly import such files. Since you're seeing "Capek" instead of "Čapek" when importing the UTF-16LE file, one of two things is probably happening. The software's internal data encoding may be Windows 1252, and it is changing "Č" to "C" on import since there is no way of representing "Č" in Windows 1252. If that is the case, it means your software is doing a more graceful degradation to "C" instead of "?" like what Excel did when saving your Windows 1252 CSV file. --OR-- it is actually the character "Č" but is rendered in a font that uses a glyph identical to "C" for that character. If a font designer didn't feel like making a bunch of seldom-used glyphs, they may have just duplicated the simple roman glyphs for those characters rather than leaving them undefined. That is probably less likely than the first scenario, since your Excel file import yields a question mark.
In either case, it means your software is behaving a little differently when importing an Excel file versus a UTF-16LE text file. The Excel file is UTF-8, and it is reading that correctly. The text file is UTF-16LE, and it is reading that correctly also. However, for the Excel file, it is changing the "Č" to a "?," and for the UTF-16LE file, it is changing it to "C." Perhaps they used some software library that's available out there for the part of their software that interprets Excel data, that library is converting to Windows 1252, and it does the more common question mark substitution. The import process for UTF-16LE is being a bit smarter about it.
There probably isn't a solution to make your software show "Č" unless it's a font problem and you can change the font, or it's converting to Windows 1252 and there is a preference somewhere that can change that. If "C" is acceptable, you can go the UTF-16LE route. The downside with UTF-16 encodings is that your file size is going to be about double what it would be with UTF-8, and if you need to look at those files with other software, they may not handle it well (UTF-8 would look fine in unaware applications except for the non-ASCII characters, which would probably still be saved correctly).
I've attached a new version of the test file. It is UTF-8 as before, but includes a UTF-8 byte order mark which may cause your software to recognize it correctly. Byte order marks are not generally recommended for UTF-8 files, but that could be a way to get your software to recognize it correctly if you don't have import options that would force it to.
Attachments
Last edited:
Similar threads
- Replies
- 9
- Views
- 2K
- Replies
- 1
- Views
- 174
- Replies
- 10
- Views
- 1K
- Replies
- 3
- Views
- 572